2026-03-14
개인 블로그에 RAG 기반 AI 챗봇 구축하기
왜 블로그에 AI 챗봇을?
블로그 글이 점점 늘어나면서, 방문자가 원하는 정보를 빠르게 찾기 어려워졌습니다. 검색 기능만으로는 한계가 있었고, 자연어로 질문하면 블로그 콘텐츠를 기반으로 답변해주는 챗봇이 있으면 좋겠다고 생각했습니다.
단순 FAQ 챗봇이 아니라, 실제 블로그 글을 읽고 이해한 뒤 답변하는 RAG(Retrieval-Augmented Generation) 방식을 선택했습니다.
전체 아키텍처
전체 파이프라인은 크게 두 단계로 나뉩니다.
1. 인덱싱 파이프라인 (글 작성 시)
블로그 글이 저장될 때마다 자동으로 실행됩니다.
글 작성 → 단락 단위 청킹 → OpenAI 임베딩(2000차원) → pgvector 저장청킹: 본문을 단락(\n\n) 단위로 분리, 각 청크에 제목/태그/날짜를 prefix로 추가
임베딩: OpenAI text-embedding-3-large 모델, Matryoshka 방식으로 2000차원으로 축소
저장: PostgreSQL pgvector 확장, HNSW 인덱스로 빠른 유사도 검색
2. 검색 + 생성 파이프라인 (질문 시)
사용자 질문 → 임베딩 → pgvector 코사인 유사도 검색 → 상위 청크 선택 → LLM 컨텍스트 주입 → 스트리밍 응답유사도 임계값 0.3 이상만 필터링하여 무관한 결과 제거
블로그 글 + 노트 테이블 모두 검색 후 합산 정렬
포트폴리오/이력서 데이터는 시스템 프롬프트에 항상 포함
핵심 구현 포인트
청킹 전략
단순히 글자 수로 자르면 문맥이 깨집니다. 단락 단위로 분리하되, 각 청크 앞에 글 제목/태그/날짜를 붙여서 검색 정확도를 높였습니다.
// 각 청크 = 제목 + 태그 + 날짜 + 본문 단락
const prefix = [title, description, tags.join(" "), datePart].filter(Boolean).join(" ");
chunks.push(`${prefix}\n\n${current.trim()}`);임베딩 차원 축소
text-embedding-3-large는 기본 3072차원인데, pgvector HNSW 인덱스의 2000차원 제한 때문에 API 호출 시 dimensions: 2000으로 축소했습니다. OpenAI의 Matryoshka Representation Learning 덕분에 정확도 손실은 0.5% 이내로 미미합니다.
SSE 스트리밍
LLM 응답을 기다렸다가 한 번에 보여주면 UX가 안 좋습니다. Server-Sent Events로 토큰 단위 스트리밍을 구현했습니다.
const stream = new ReadableStream({
async start(controller) {
for await (const chunk of completion) {
const content = chunk.choices[0]?.delta?.content;
if (content) {
controller.enqueue(
encoder.encode(`data: ${JSON.stringify({ content })}\n\n`)
);
}
}
},
});시스템 프롬프트 설계
단순히 "답변해줘"가 아니라, 톤/보안/컨텍스트 우선순위까지 세밀하게 설계했습니다.
톤: "~요" 체로 친근하지만 전문적으로
컨텍스트 우선순위: 경력 질문 → 포트폴리오/이력서 우선, 기술 질문 → 블로그 글 우선
보안: 프롬프트 공개 거부, 역할 이탈 방지, 개발 외 주제 거절
채용 담당자 대응: 면접형 질문에 STAR 패턴으로 구체적 성과 답변
기술 스택
영역기술프레임워크Next.js 15 (App Router)임베딩OpenAI text-embedding-3-large (2000차원)벡터 DBPostgreSQL + pgvector (HNSW 인덱스)LLMGroq (Llama 3.3 70B)스트리밍Server-Sent Events (SSE)배포Vercel + Neon PostgreSQL
운영하면서 겪은 문제들
한국어 응답에 한자가 섞이는 문제
Llama 모델이 한국어 응답 중 간혹 중국어 한자나 일본어 가나를 섞어서 출력했습니다. 시스템 프롬프트에 규칙을 추가하고, 서버 사이드에서 CJK 문자를 필터링하는 이중 방어를 적용했습니다.
// 스트리밍 중 CJK 한자/가나 제거
const content = raw.replace(/[\u4E00-\u9FFF\u3040-\u309F\u30A0-\u30FF]/g, "");무관한 참고 글이 뜨는 문제
벡터 검색은 항상 "가장 유사한" 결과를 반환하는데, 유사도가 낮아도 결과가 나옵니다. 코사인 유사도 0.3 미만은 필터링하도록 임계값을 설정했습니다.
Groq 무료 티어 한계
일일 100K 토큰 제한에 걸려서 Dev Tier로 업그레이드했습니다. 월 1,000건 대화 기준 약 $3 수준으로 개인 블로그에는 충분합니다.
다이어그램
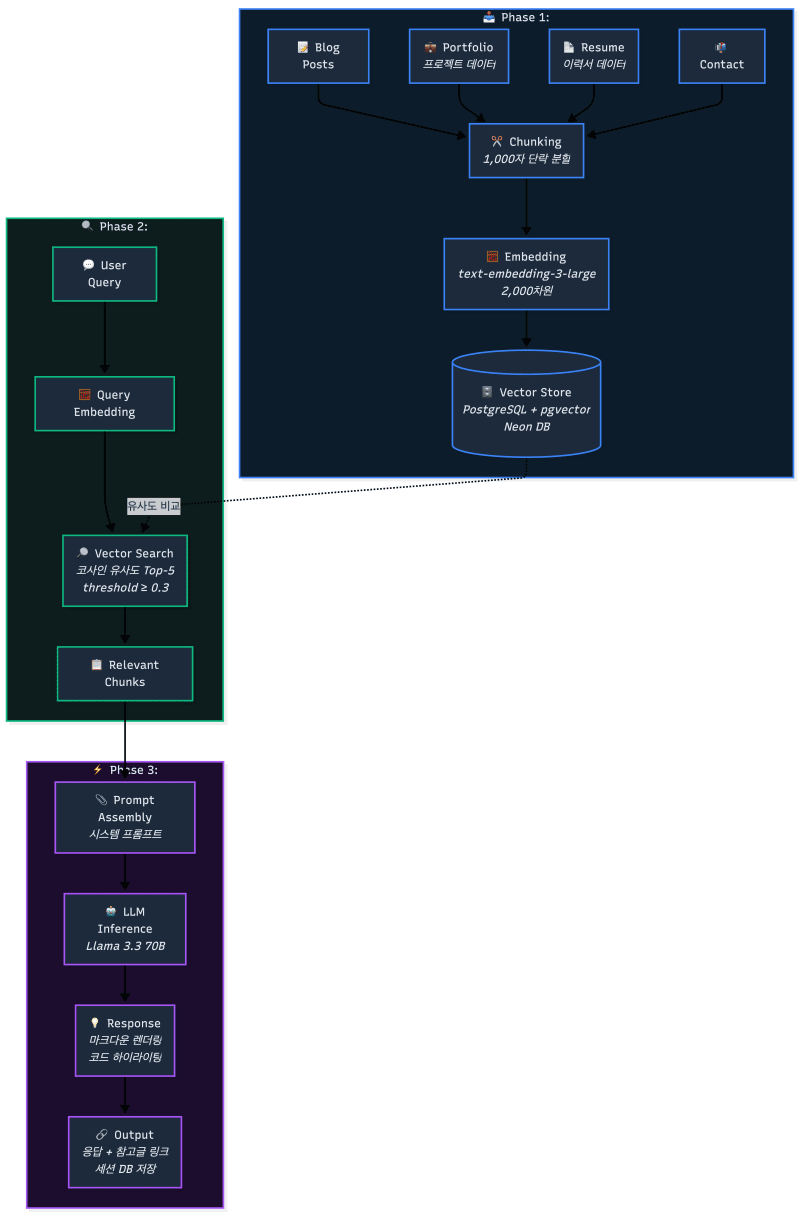
마무리
RAG 챗봇을 직접 구축하면서 임베딩, 벡터 검색, 프롬프트 엔지니어링의 실전 경험을 쌓을 수 있었습니다. 외부 SaaS 없이 pgvector + Groq 조합으로 저비용 RAG를 구현할 수 있다는 점이 만족스럽습니다.
블로그 우측 하단의 챗봇 버튼을 눌러서 직접 사용해보세요!
관련 글
벡터 유사도 기반블로그 검색에 임베딩 기반 벡터 유사도를 도입한 이야기
LIKE 검색의 한계를 넘어 OpenAI 임베딩과 pgvector를 활용한 하이브리드 검색을 구현한 과정. 청킹 전략, 스코어링 방식, 점수 보정까지.
100% 일치pgvector로 블로그 관련 글 추천 구현하기
PostgreSQL의 pgvector 확장과 OpenAI 임베딩을 활용해 블로그에 관련 글 추천 기능을 구현한 과정을 정리합니다.
97% 일치OpenAI vs Gemini Embedding 2 — 임베딩 모델 비교 분석
text-embedding-3-large와 Gemini Embedding 2의 가격, 성능, 멀티모달 지원을 비교하고 실제 프로덕션에서의 선택 기준을 정리한다.